We are starting to build momentum on the ERC Identity Compression project, exploring how identity is “written in” to social information via social interaction; how this reduces complexity; and thus social information (like attitudes) become a substrate for identity. We’ll use ideas from information theory (compressibility; information entropy), simulations, network methods, and ordinary experiments. Like DAFINET, it will have an applied maths team working closely with a social science team to develop a novel take on social processes.
In this post I want to collate what we’ve written on the topic in two recent papers; more of an info-dump than a blog post, but perhaps useful for someone trying to figure out what we mean when we say “Identity Compression” or “compressibility.”
This is how we (Durrheim & Quayle, 2025, CC-BY-NC-ND 4.0) described the concept of compressibility in our recent Human Murmuration paper:
I also explain the idea in Social Identity Networks:
“To explain: if two contemporary Americans discover each other’s attitudes on abortion, immigration, gun control or other “hot” topics, they can guess each-other’s political identities with astonishing accuracy (Lüders, Carpentras, et al., 2024). On the other hand, if two Swiss people learn each-other’s attitudes to guns they will be better able to guess each-other’s gender than political identity.
How is this possible? It depends on the synchronization of attitudes in groups such that various combinations of attitudes become most associated with certain identities; thus identities become dimensions of compressibility in the collective social information system, and small amounts of information can be used to make reasonable guesses about other features by exploiting associational redundancy in the system (Durrheim & Quayle, 2025).
In this sense, social polarization is a feature of compressible social information that allows the recognition of an agent’s group identity from a small number of key attitudes, addressing the problem of how people use expressed attitudes to tell “us” from “them” in a system structured to facilitate this social operation. This is important because, once attitudes like “support for electric cars” or “approval of vaccines” become properties of groups, then attitude change becomes an intergroup process.”
Of course, this concept is related to well-known approaches in political science (cleavages; contraint etc.) and psychology (stereotypes, heuristics, schemas etc.); but provides a mathematical umbrella concept that allows us to conceptualize humans-in-information as a dynamic co-constitutive system, and also allows us to imagine how social information is functional in the coordination of social activity.
I think this is one of those ideas that is both simple and obvious; but can really help us to conceptualize the relationship between individual experience and (dynamic) social structure.
References:
Durrheim, K., & Quayle, M. (2025). Human murmuration: Group polarisation as compression in interaction-language dynamics captured by large language models. European Review of Social Psychology, 1–40. https://doi.org/10.1080/10463283.2025.2499332
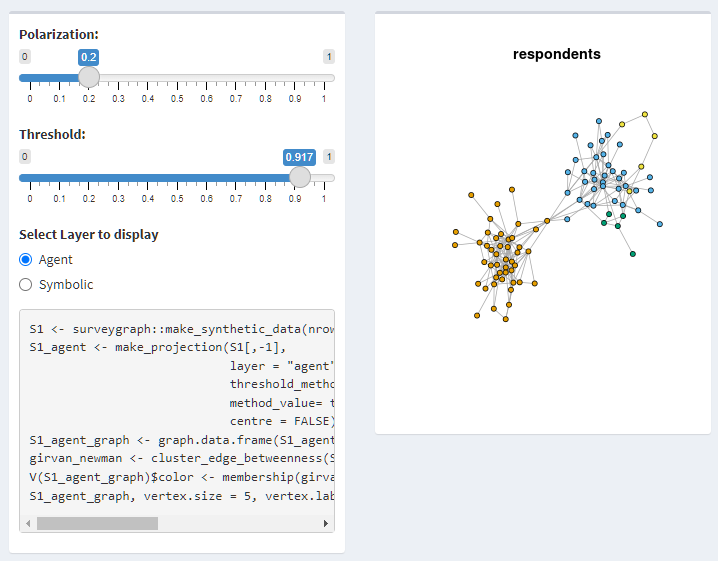
Some news: good progress being made on the SurveyGraph package for R and Python. Available on Cran soon! In the meantime, check out the Shiny app by Cillian McHugh that lets you play around with it a bit: https://cillianmacaodh.shinyapps.io/surveygraph/
Delighted to have secured an ERC Consolidator grant for ID-COMPRESSION:
Starting in January 2025, this project will develop and test a framework for understanding how identity is “written in” to social information via social interaction; how this reduces complexity; and thus social information (like attitudes) become a substrate for identity. Of course, this is closely related to familiar social psychology topics explaining how people generate simplified representations of the world — like categorization, stereotyping, heuristics etc. — but is more basic, and provides a fundamental explanation for the social process of simplification and its social functions. Mini-spoiler: the framework treats social interaction as a form of computation, with compressible identity-laden information as a product.
Like DAFINET, it will have an applied maths/network science/information team working closely with a social science team to develop a novel take on social processes.
We’ll be recruiting two Postdocs (probably up to five years) and two funded PhD students in the second half of 2024 for a January 2025 start, so keep an eye on our social media accounts for information and announcements.
It was July 2018 when I blogged the great news about an ERC Starter grant to develop a network theory of attitudes. And then I got busy, I guess, because I didn’t post here again until October 2021. We’re now about halfway through the grant, so I thought this would be a good time to write a bit about what we’ve done, and what we have left to do.
The first thing we did with the money was to start assembling an interdisciplinary team, with people trained in social psychology, mathematics, statistics, physics, and computational modelling. Our aim was to build a supportive and collegial team, and I think we’ve achieved that. Regardless of our successes and failures, we enjoy working together.
Our focus from the start was on evaluating the applicability of the proposed network models to the phenomenon (theory development), and experimentally confirming the proposed psychological mechanisms linking attitudes and social identity (basic human experiments). We’ve made good progress on both of these aims.
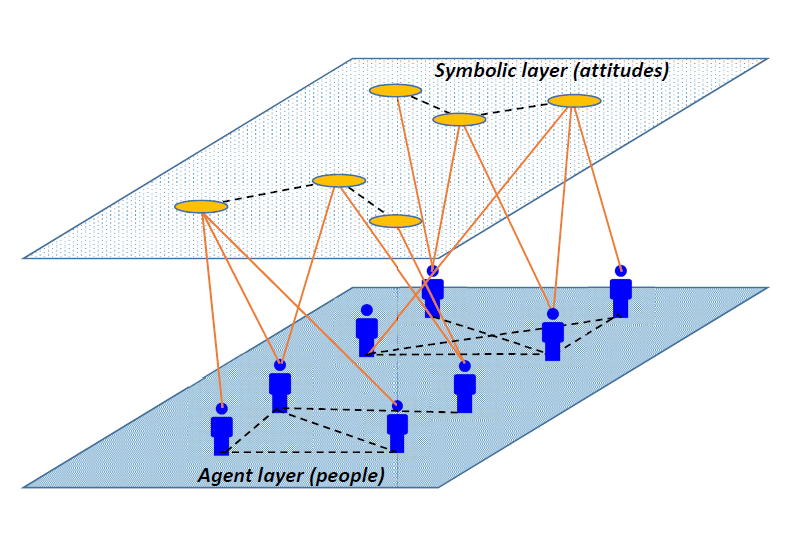
The core idea of the proposal is that people are linked by the attitudes they jointly hold, and that attitudes become socially connected when they are jointly held by people.
People-connected-by-attitudes in the Bangladesh vaccine opinion network
We can also view this social structure from the “other side,” and map connections between attitudes (on the basis of being jointly held by people). This produces a network-view of a set of opinions similar to those generated in belief-network analysis, but with fewer statistical assumptions. Here are the connections between attitudes in the same Bangladeshi vaccine network:
Attitudes-connected-by-people in the Bangladesh vaccine opinion network
An important feature of the method is that we accept that these two views are inseperable features of the same social structure. You can read more about this method in our preprint. (And note that we have realized that we are walking in the footsteps of the sociologist Ronald Breiger who referred to this as “the duality of persons and groups.”)
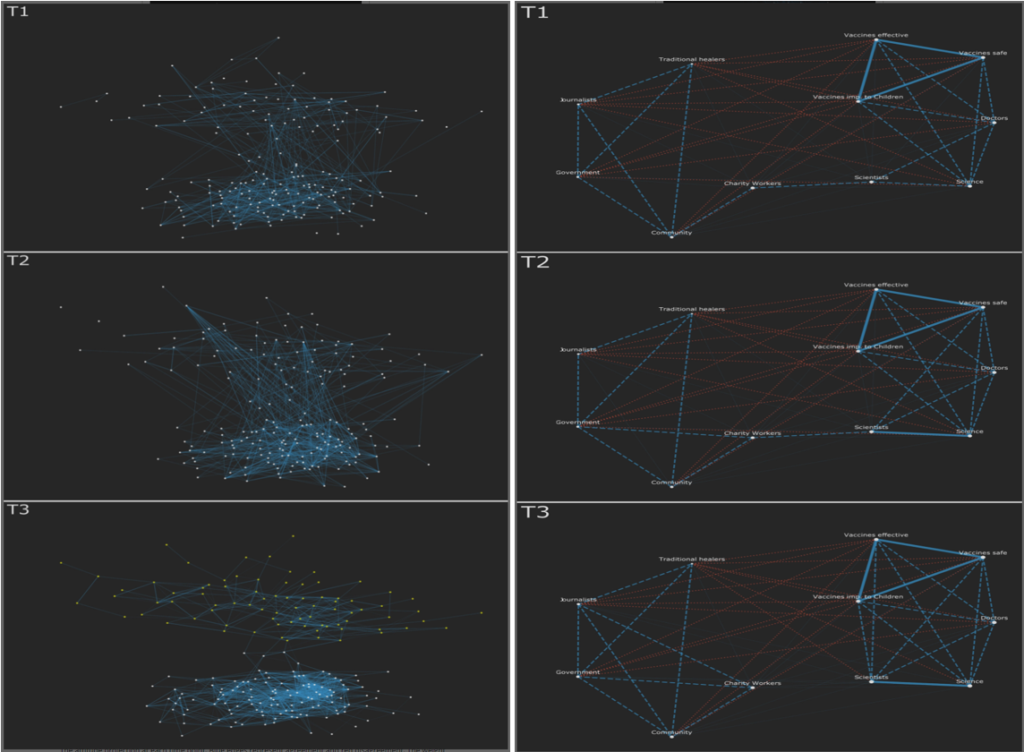
We have applied this method to empirical attitude data collected in the first wave of the COVID pandemic in the UK. We were able to detect opinion-based groups, track their evolution over time, and show that membership of these dynamic opinion-based groups was associated with group-relevant health behaviours (doi:10.1111/bjso.12396). We think that the method is providing a unique, if incomplete, window on the relation between opinions, group identity, and behaviour.
Dynamic opinion-based groups evolving during first wave of the COVID pandemic in the UK, viewed as people-connected-by-opinions (left) and opinions-connected-by-people (right)
We have done some work exploring the relationship of the method to other cluster-detection methods (e.g. hierarchical cluster analysis and stochastic block models), and found that we get broadly similar results but with the advantage of being able to locate individuals precisely in the structural opinion-space (see our preprint; currently in press at Advances in Complex Systems). The method also lends itself to detecting and quantifying opinion-based (i.e. ideological) polarization; and, as long as there is synchronization on opinions within groups, can even detect polarization without extremism (e.g. when two groups hold moderate opinions and yet never quite agree).
Perhaps most importantly, it gives us the ability to produce very cool visualisations :D!
In our proposal, we said we would develop agent based models (ABM’s) implementing this type of social structure. With the help of experts who attended our project-launch workshop, we realized that Axelrod’s classic model of cultural diffusion natively relies on a bipartite network structure of people connected by attitudes. We extended this model, introducing a multidimensional equivalent of an agreement threshold, and found that the model generates plausible clusters similar to those observed in real data (doi:10.1371/journal.pone.0233995). We have shown that this model (where network edges represent similarity in opinions), is relatively impervious to underlying social network topology (e.g. friendship links) and we can therefore use this agent-based model to simulate opinion dynamics in realistic social systems even when we don’t know the social connections between people (doi:10.1016/j.physa.2021.126086). Our next step in this line of research is to see whether we can use the agent-based model to say anything useful about identity and opinion dynamics in real social systems (initially observed via surveys).
However, while the research above is very promising, it doesn’t tell us much about whether people actually perceive the world in this way, or whether the social structures we observe using these methods make any difference to how people socially identify or act in the world.
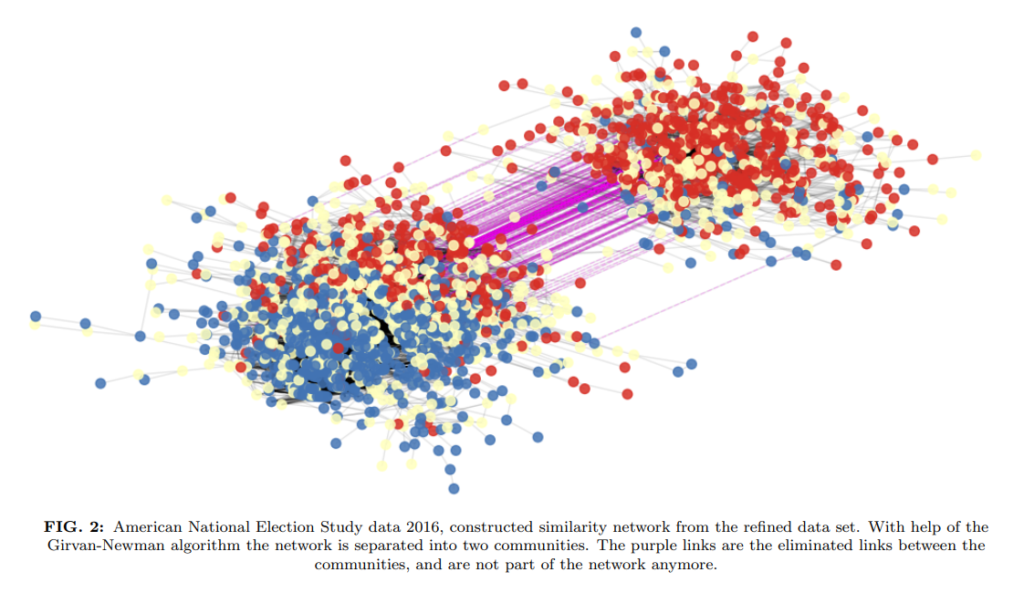
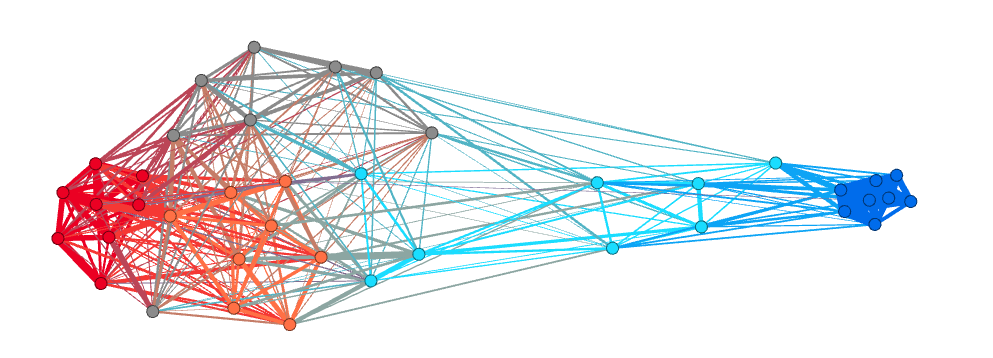
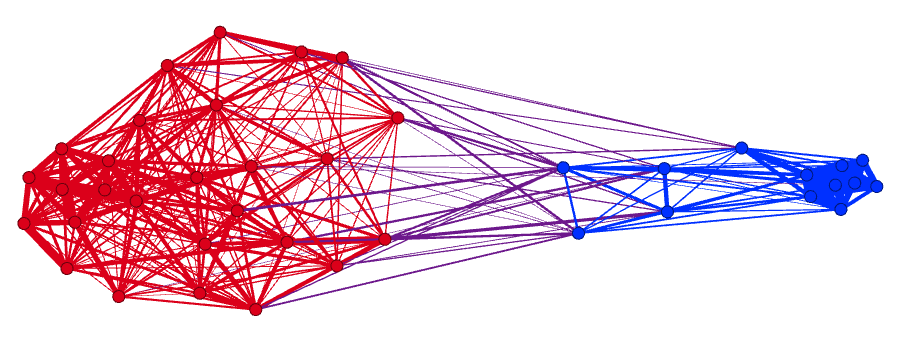
To examine these questions, we developed a new method that allows us to extract and illustrate belief networks among different groups in what we are calling an “attitude-space” (see our preprint). The graphic below shows a partisan attitude space of different political partisan groups in the US, based on participants’ item responses. To test whether attitudes can serve as marker of social identities, we correlated participants’ item responses with their self-reported political identification that the two evident attitude clusters map to Democrat´s and Republican´s attitude positions. In a second step, we exposed participants to other people´s attitude positions to see how the expression of attitudes by others relates to social perceptions. Our results showed that the extent of distance between one´s own attitude position in a network and the position of an attitude expressed by another person correlated reliably with how people socially categorize and emotionally perceive others (manuscript in preparation). We believe that this approach offers a novel view on the complex interplay between attitudes and polarization, both affective and ideological.
Top: An extracted “Attitude Space” based on participants responses to 8 political items taken from the ANES survey. The network shows the correlation of responses with strong disagreement (dark blue), modest disagreement (pale blue), neutral (grey), modest agreement (orange), and strong agreement (red); Above: The same network, showing participants’ self-categorization as democrat (blue) and republican (red).
While correlational insights like these help us understand how attitudes translate into social identity phenomena, a main focus of our current work is on social experiments that test the causal hypotheses on attitude-identity dynamics offered by our model.
To test the psychological basis of opinion-based group identification, we wanted to develop a version of the minimal groups paradigm where people have the chance to agree and disagree with collaborators on novel statements that they’ve never heard before. This should allow us to test whether (a) joint agreement on attitudes promotes a sense of ingroup identification (over and above the identification from simply belonging to a minimal group) and (b) whether opinions that are incorporated into these minimal group identities are more strongly held as a consequence. To do so, we have developed a method for generating novel attitude statements — attitudes to which people have not yet been exposed and are unlikely to have a pre-existing opinion on (for example, “a circle is a noble shape”). We have piloted a selection of these, and now have a battery of novel opinions (or “Attitude sets”) to deploy in our experiments.
Despite Covid-related delays to our virtual interaction experiments (which previously relied on people participating together in a lab), we have run three experiments with human participants. These demonstrate that:
(1) Sharing novel opinions (and more specifically, expressing agreement on such opinions) results in people experiencing a sense of shared group identity.
(2) The sense of identification produced in opinion-based groups is stronger than that produced by the conditions in classical “minimal group” conditions where groups are differentiated on arbitrary dimensions (like preference for one painting over another).
(3) People come to have more certainty about attitudes that are associated with an emerging group identity.
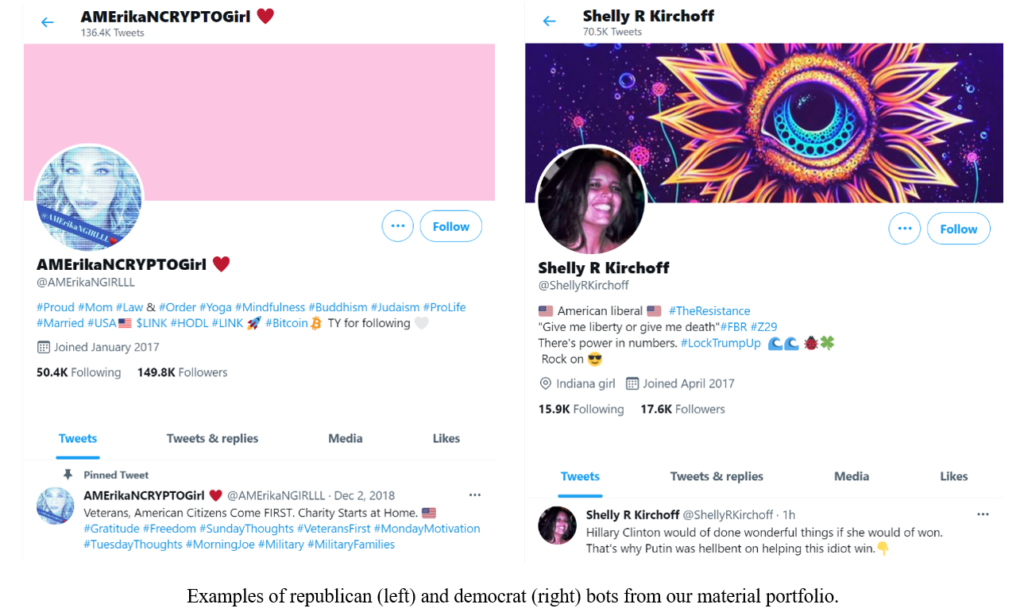
We have also started to explore the role of attitudes in social media behaviour. We have identified a portfolio of real political bots, using available tools like the botometer, which we use to generate materials for experiments. In one of our ongoing projects, we expose participants to different bot and human accounts, and test whether attitude (dis)agreement between people´s own opinions and those held by an account profile can predict misperceptions of bot accounts as real users and vice versa. In other words, are people more willing to accept accounts as human if their posts are ideologically aligned with the participant’s own identity? Based on these emerging results we will design further studies to trial “micro interventions” that may help combat the spread of misinformation through online networks.
Examples of republican (left) and democrat (right) bots from our material portfolio.
In the meantime, the VIAPPL software platform has been updated to allow a novel network game where participants exchange opinions and we will be piloting this in the next months. The platform offers the unique opportunity to study social identity effects in experimentally controlled social interactions settings, hence providing a maximum of internal validity. While the key focus of the VIAPPL research avenue will lie on the understanding of group formation through attitude alignment, it offers plenty of opportunities for other factors to explore. Manipulations of audiences (e.g. based on attitude homogeneity vs. divergence similar to social network sites), motivational states (e.g. zero-sum games, threats), or different attitude formats (e.g. “neutral” attitudes, socio-political attitudes) are just a few ideas to name for the beginning as possibilities are expanding through internal and external input from our team as well as from our network of collaborators.
So, are we halfway there? overall, our results exceed the expectations I had for the halfway mark when I wrote the proposal. There are some areas where we are lagging behind, but others where we’ve already gone well beyond what we could imagine at the start. We’re feeling excited about how these ideas can be applied and extended well beyond the scope of this grant.
We’re currently (October 2021) recruiting a new member of our team, and looking forward to seeing what this person brings to this programme of research! While we hope that people are excited by the work we’re doing, we are also aware that the complexity can be quite overwhelming to start with. Multidisciplinary work is very exciting, but we should be clear that no single person in the group understands every feature of the research we’re doing. The social psychologists lean heavily on the mathematicians/statisticians; and they rely on us for linking their models to social theory. In fact, that’s the thing I’ve enjoyed the most about the first half of this ERC grant – the great privilege of being able to work on ideas much bigger than I could have tackled alone.
[Attribution: Thanks to Adrian Lüders for additions to the section on the social experiments; and some great images from his current studies. All of the research reported here is a team effort! Please see references below for authorship. Disclaimer: some of the text is repeated in the ERC mid-term scientific report, which you will find on the European Commission Cordis website. For more information on the studies reported above, see the publication & impact page on the DAFINET website.]
References:
Carpentras, D., Lueders, A., & Quayle, M. (2021). A method for exploring attitude systems by combining belief network analysis and item response theory(Resin) [Preprint]. PsyArXiv. https://doi.org/10.31234/osf.io/uzdcg
Dinkelberg, A., MacCarron, P., Maher, P. J., & Quayle, M. (2021). Homophily dynamics outweigh network topology in an extended Axelrod’s Cultural Dissemination Model. Physica A: Statistical Mechanics and Its Applications, 578, 126086. https://doi.org/10.1016/j.physa.2021.126086
Dinkelberg, A., O’Sullivan, D., Quayle, M., & MacCarron, P. (2021). Detecting opinion-based groups and polarisation in survey-based attitude networks and estimating question relevance. ArXiv:2104.14427 [Physics]. http://arxiv.org/abs/2104.14427
MacCarron, P., Maher, P. J., Fennell, S., Burke, K., Gleeson, J. P., Durrheim, K., & Quayle, M. (2020). Agreement threshold on Axelrod’s model of cultural dissemination. PLOS ONE, 15(6), e0233995. https://doi.org/10.1371/journal.pone.0233995
MacCarron, P., Maher, P. J., & Quayle, M. (2020). Identifying opinion-based groups from survey data: A bipartite network approach. ArXiv:2012.11392 [Physics]. http://arxiv.org/abs/2012.11392
Maher, P. J., MacCarron, P., & Quayle, M. (2020). Mapping public health responses with attitude networks: The emergence of opinion‐based groups in the UK’s early COVID‐19 response phase. British Journal of Social Psychology, 59(3), 641–652. https://doi.org/10.1111/bjso.12396
Delighted to announce an ERC starter grant to develop a network theory of attitudes. Here’s the abstract:
Understanding the coordination of attitudes in societies is vitally important for many disciplines and global social challenges. Network opinion dynamics are poorly understood, especially in hybrid networks where automated (bot) agents seek to influence economic or political processes (e.g. USA: Trump vs Clinton; UK: Brexit). A dynamic fixing theory of attitudes is proposed, premised on three features of attitudes demonstrated in ethnomethodology and social psychology; that people: 1) simultaneously hold a repertoire of multiple (sometimes ambivalent) attitudes, 2) express attitudes to enact social identity; and 3) are accountable for attitude expression in interaction. It is proposed that interactions between agents generate symbolic links between attitudes with the emergent social-symbolic structure generating perceived ingroup similarity and outgroup difference in a multilayer network. Thus attitudes can become dynamically fixed when constellations of attitudes are locked-in to identities via multilayer networks of attitude agreement and disagreement; a process intensified by conflict, threat or zero-sum partisan processes (e.g. elections/referenda). Agent-based simulations will validate the theory and explore the hypothesized channels of bot influence. Network experiments with human and hybrid networks will test theoretically derived hypotheses. Observational network studies will assess model fit using historical Twitter data. Results will provide a social-psychological-network theory for attitude dynamics and vulnerability to computational propaganda in hybrid networks.
The theory will explain:
(a) when and how consensus can propagate rapidly through networks (since identity processes fix attitudes already contained within repertoires);
(b) limits of identity-related attitude propagation (since attitudes outside of repertoires will not be easily adopted); and
(c) how attitudes can often ‘roll back’ after events (since contextual changes ‘unfix’ attitudes).
The proposed project capitalizes on multi-disciplinary advances in attitudes, identity and network science to develop the theory of Dynamic Fixing of Attitudes In NETworks (DAFINET).
Specifically, DAFINET integrates advances in identity research from social psychology, models of attitudes from ethnomethodology (a branch of sociology), and multilayer network modelling from network science to propose a novel theory of opinion dynamics and social influence in networks. DAFINET will have impact in a broad range of disciplines where attitude propagation and social influence is of concern, including in economics, sociology, social psychology, marketing, political science, health behaviour, environmental science, and many others.
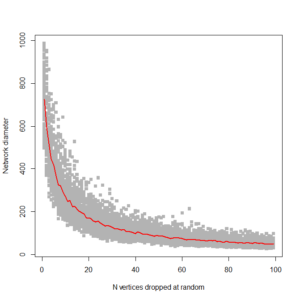
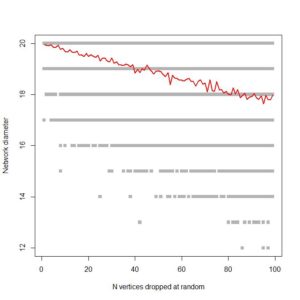
I’ve been asked by reviewers to stress test two networks following Jeong & Barabási (2000). Critically the reviewers asked for an exploration of how network diameter changed as progressively larger numbers of nodes were randomly dropped from the networks.
Although the netboot library makes it trivial to do a case-drop bootstrap on a network, it reports a limited set of network statistics and diameter is not one of them.
Here’s an attempt to run a stress test on network diameter for a small (1000 node) randomly generated ring network. I’m sure there are more efficient ways of doing this, and I’m concerned that the algorithm might struggle with the large real-world networks I’ll be applying it to, but I’m proud of the pretty output for now:
library(pacman)
library(tidyverse)
library(tidygraph)
library(igraph)
library(ggplot2)
#Function graphdropstats accepts graph object and number of cases to drop
#drops ndrop cases(vertices) (using uniform random distribution to identify nodes to drop)
#then returns statistic on subgraph, in this case diameter
# V(graph) gives list of nodes in graph
# vcount(graph) gives number of vertices, but more efficient to get this from length of V(graph)
graphdropstats <- function(graph,ndrop){
keepnodes<-V(graph) #vector of vertex ID's in graph
droplist<-sample(as_ids(keepnodes),ndrop)
keepnodes<-keepnodes[-droplist] #vector of positions in keepnodes to drop
samplegraph<-induced_subgraph(graph,keepnodes)
return(diameter(samplegraph))
}
#generate graph for testing
graph1<-create_ring(1000)
## sampling with nreps replications, dropping ndrop nodes at random and saving statistics;
## and incrementing ndrop each time until ndropstop
nreps=100
ndropstop=100
ndrop=1
allresults<-vector("numeric", nreps)
for (ndrop in 1:ndropstop){
result<-vector("numeric", nreps)
for (i in 1:nreps) {
result[i] <- graphdropstats(graph1,ndrop)
}
if(ndrop > 1) allresults<-rbind(allresults,result)
}
allresults <- allresults[-1,] #drop first row of matrix which otherwise is blank
#allresults
matplot(allresults, type='p', pch=15, col=c("gray70"),xlab="N vertices dropped at random", ylab="Network diameter")
index<-1:(ndropstop-1)
lines(index, rowMeans(allresults), col = "red", lwd = 2)
#Edit 27/3/2018: bugfix
This gives us this plot:
…. which is pretty much what I’m looking for. It shows, as expected, that ring networks are highly vulnerable to node dropout. Compare to a 1000 node scale-free network:
Fingers crossed that it’s efficient enough to run on large co-authorship networks!
Albert, R., Jeong, H., & Barabási, A.. (2000). Error and attack tolerance of complex networks. Nature, 406(6794), 378–382. [Bibtex]
@article{Jeong2000, title={Error and attack tolerance of complex networks}, volume={406}, url={http://dx.doi.org/10.1038/35019019}, DOI={10.1038/35019019}, number={6794}, journal={Nature}, publisher={Springer Nature}, author={Albert, Réka and Jeong, Hawoong and Barabási, Albert-László}, year={2000}, month={Jul}, pages={378–382}}
For as long as I’ve been doing qualitative analysis I’ve been looking for ways to automate transcription. When I was doing my masters I spent more time (fruitlessly) looking for technical solutions than actually doing transcription. Speech recognition has come a a long way since then; perhaps it’s time to try again?
I came across a blog post recently that suggested it’s becoming possible using the Google Speech API. This is the same deep-learning model that powers Android speech recognition, so it seems promising.
After setting up a GCloud account (currently with $300 free credit; not sure how long that will last) installing the R libraries and running some text is simple:
#install package; run first time or to update package....
#devtools::install_github("ropensci/googleLanguageR")
library(googleLanguageR)
Once you’ve authorized with GCloud (a single line of code) the transcription itself requires a single command:
gl_speech("path to audio clip")
I tested it with a really challenging task: a 15 second clip of the Fermanagh Rose from the 2017 Rose of Tralee:
startTime endTime word
1 0s 1.500s things
2 1.500s 1.600s are
3 1.600s 2.600s boyfriend
4 2.600s 2.700s and
5 2.700s 3.200s see
6 3.200s 3.600s uncle
7 3.600s 7.100s supposed
8 7.100s 7.300s to
9 7.300s 7.400s be
10 7.400s 7.500s on
11 7.500s 12.200s something
12 12.200s 12.700s instead
13 12.700s 13s so
14 13s 14.600s Big
15 14.600s 14.900s Brother
16 14.900s 15.400s big
17 15.400s 15.800s buzz
18 15.800s 16.300s around
19 16.300s 17.300s Broad
20 17.300s 17.600s range
21 17.600s 17.900s at
22 17.900s 24.300s Loughborough
23 24.300s 24.700s bank
24 24.700s 25.100s whereabouts
25 25.100s 25.100s in
26 25.100s 25.600s Fermanagh
27 25.600s 27.700s between
28 27.700s 28.300s Fermanagh
29 28.300s 28.800s Cavan
30 28.800s 29.700s and
31 29.700s 29.800s I
32 29.800s 30.100s live
33 30.100s 30.400s action
34 30.400s 30.600s the
35 30.600s 30.900s road
36 30.900s 31.500s on
37 31.500s 31.800s for
38 31.800s 32s the
39 32s 32.200s Marble
40 32.200s 32.300s Arch
41 32.300s 32.400s Caves
42 32.400s 33.800s and
43 33.800s 34.400s popular
44 34.400s 34.600s culture
Honestly, that’s not bad — although not quite useable. It’s certainly a good base to start transcribing from. I was not expecting it do deal so well with fast speech and regional dialects. Perhaps transcription nirvana will arrive soon; not quite here yet, but quite astonishing that such powerful language processing is so easily accomplished.
This is a very exciting find: a way to automatically generate a publications page on a WordPress blog from a bibtex file.
I’ve used Jabref to manage my own publication record for years now. Papercite pulls the most recent version of the Jabref database (a bibtex file) via a Dropbox link and automatically generates my publication page (see it in action here). Here’s the script in the WordPress page that does the work:
{bibtex highlight=”Michael Quayle|M. Quayle|Mike Quayle|Quayle|Quayle M.” template=av-bibtex format = APA show_links=1 process_titles=1 group=year group_order=desc file=https://www.dropbox.com/s/2ol9lo2rh52bo6c/1.MQPublications.bib?dl=1}
(Note: I’ve replaced the square brackets with curly braces so that the publications page doesn’t render in this post about the publications page; the curly brackets above need to be square brackets in order for the script to run.)
Now, when I update my bibtex record with new publications (which I would be doing anyway) my publications page automatically shows the most recent updates.
Fingers-crossed that this continues to work when Dropbox changes its web-rendering policy in September….
I’m excited to be travelling to South Africa for the VIAPPL symposium at the first Pan-African Psychology Union Congress in Durban on the 19th of September.
We’ll follow that up with a VIAPPL researcher’s conference with collaborators from the University of KwaZulu-Natal, University of Groningen and the University of Limerick (me).
Contact me (mike.quayle<<at>>ul.ie) for more information on these.